

Can ChatGPT predict the future? Training AI to figure out what happens next
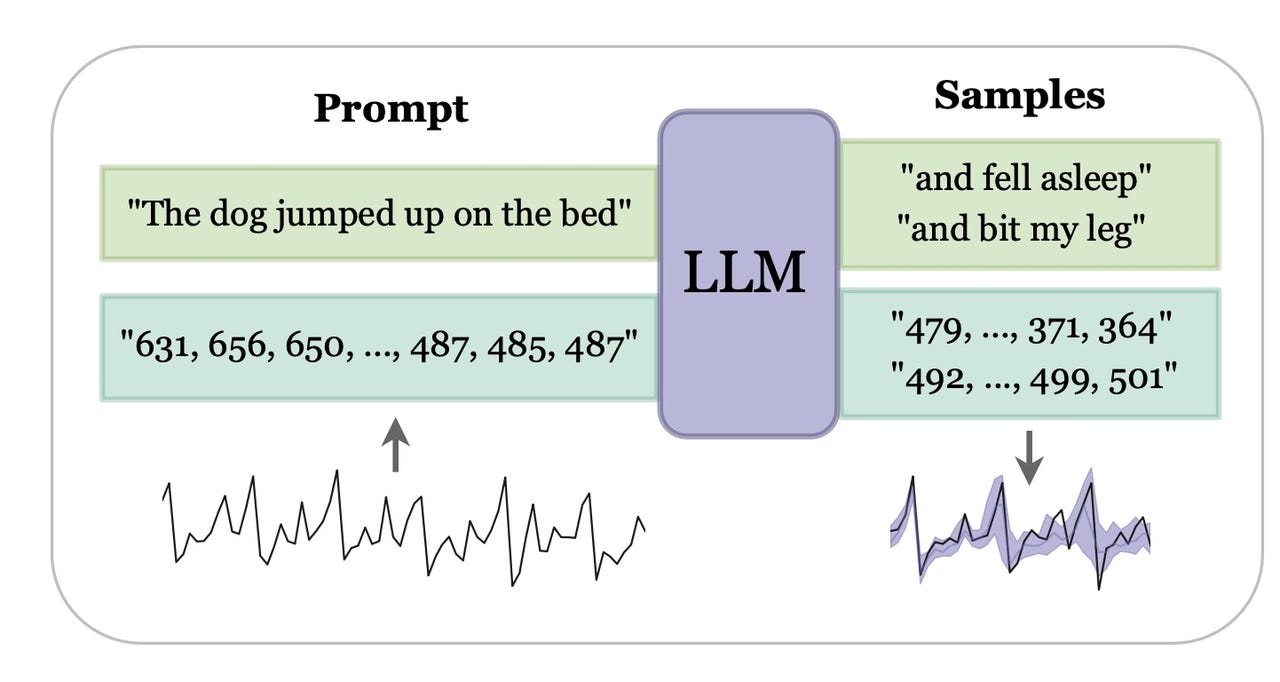
NYU’s LLMtime program finds the next likely event in a sequence of events, as represented in strings of numeric digits. New York University
Today’s generative artificial intelligence programs, tools such as ChatGPT, are on course to produce many more kinds of results than just text, as ZDNET has explored in some depth.
One of the most important of those “modalities,” as they’re known, is what’s called time series data — data that measures the same variables at different points in time to spot trends. Data in a time series format can be important for things such as tracking patient medical history over time with the entries made by a physician in a chart. Doing what’s called time series forecasting means taking the historical data and predicting what’s happening next; for example: “Will this patient get better?”
Also: ChatGPT seems to be confused about when its knowledge ends
Traditional approaches to time series data involve software specially designed for just that type of data. But now, generative AI is gaining a new ability to handle time series data in the same way it handles essay questions, image generation, software coding, and the various other tasks at which ChatGPT and similar programs have excelled.
In a new study published this month by Nate Gruver of New York University and colleagues from NYU and Carnegie Mellon, OpenAI’s GPT-3 program is trained to predict the next event in a time series similar to predicting the next word in a sentence.
“Because language models are built to represent complex probability distributions over sequences, they are theoretically well-suited for time series modeling,” write Gruver and team in their paper, “Large Language Models Are Zero-Shot Time Series Forecasters,” posted on the arXiv pre-print server. “Time series data typically takes the exact same form as language modeling data, as a collection of sequences.”
The program they created, LLMTime, is “exceedingly simple,” write Gruver and team, and able to “exceed or match purpose-built time series methods over a range of different problems in a zero-shot fashion, meaning that LLMTime can be used without any fine-tuning on the downstream data used by other models.”
Also: Generative AI will far surpass what ChatGPT can do. Here’s everything on how the tech advances
The key to building LLMTime was for Gruver and team to re-think what’s called “tokenization,” the way that a large language model represents the data it’s working on.
Programs such as GPT-3 have a certain way that they input words and characters, by breaking them up into chunks that can be ingested one at a time. Time series data is represented as sequences of numbers, such as “123”; the time series is just the pattern in which such digit sequences occur.
Given that, the tokenization of GPT-3 is problematic because it will often break up those strings into awkward groupings. “For example, the number 42235630 gets tokenized as [422, 35, 630] by the GPT-3 tokenizer, and changes by even a single digit can result in an entirely different tokenization,” relate Gruver and team.
To avoid those awkward groupings, Gruver and team built code to insert white space around every digit of a digit sequence, so that each digit would be encoded separately.
Also: 3 ways AI is revolutionizing how health organizations serve patients. Can LLMs like ChatGPT help?
They then went to work training GPT-3 to forecast the next digit sequence in real-world examples of time series.
Any time series is a sequence of things that occur one after the other, such as, “The dog jumped down from the couch and ran to the door,” where there’s one event, and then another. An example of a real data set about which people want to make predictions would be predicting ATM withdrawals based on historical withdrawals. A bank would be very interested in predicting such things.
ATM withdrawal predicting is, in fact, one of the challenges of a real-time series competition like the Artificial Neural Network & Computational Intelligence Forecasting Competition, run by the UK’s Lancaster University. That set of data is simply strings and strings of numbers, in this form:
T1: 1996-03-18 00-00-00 : 13.4070294784581, 14.7250566893424, etc.
The first part is obviously the date and time stamp for “T1,” representing the first moment in time, and what follows are amounts (separated by dots, not commas, as is the case in European notation). The challenge for a neural net is to predict, given thousands or even millions of such items, what would happen in the next moment in time after the last example in the series — how much will be withdrawn by clients tomorrow.
Also: This new technology could blow away GPT-4 and everything like it
The authors relate, “Not only is LLMTime able to generate plausible completions of the real and synthetic time series, it achieves higher likelihoods […] in zero-shot evaluation than the dedicated time series models […]” that have been created for decades.
The LLMtime program finds where a number is in a distribution, a distinct pattern of recurrence of numbers, to conclude whether a sequence represents one of the common patterns such as “exponential” or Gaussian. New York University
However, one of the limitations of the large language models, Gruver and team point out, is that they can only take in so much data at a time, known as the “context window.” To handle larger and larger time series, the programs will need to expand that context window to many more tokens. That’s a project being explored by numerous parties, such as the Hyena team at Stanford University and Canada’s MILA Institute for AI and Microsoft, among others.
Also: Microsoft, TikTok give generative AI a sort of memory
The obvious question is why a large language model should be good at predicting numbers. As the authors note, for any sequence of numbers such as the ATM withdrawals, there are “arbitrarily many generation rules that are consistent with the input.” Translation: There are so many reasons why those particular strings of numbers might appear, it would be hard to guess what the underlying rule is that accounts for them.
The answer is that GPT-3 and its ilk find the rules that are the simplest among all possible rules. “LLMs can forecast effectively because they prefer completions derived from simple rules, adopting a form of Occam’s razor,” write Gruver and team, referring to the principle of parsimony.
Sometimes the GPT-4 program is led astray when it tries to reason out what the pattern of a time series is, showing that it doesn’t actually “understand” the time series in the traditional sense. New York University
That doesn’t mean that GPT-3 really understands what’s going on. In a second experiment, Gruver and team submitted to GPT-4 (GPT-3’s more powerful successor) a new data set they made up using a particular mathematical function. They asked GPT-4 to deduce the mathematical function that produced the time series, to answer the question, “whether GPT-4 can explain in text its understanding of a given time series,” write Gruver and team.
They found GPT-4 was able to guess the mathematical function better than random chance, but it produced some explanations that were off the mark. “The model sometimes makes incorrect deductions about the behavior of the data it has seen, or the expected behavior of the candidate functions.” In other words, even when a program such as GPT-4 can do well at predicting the next thing in a time series, its explanations end up being “hallucinations,” the tendency to offer incorrect answers.
Also: Implementing AI into software engineering? Here’s everything you need to know
Gruver and team are enthusiastic about how time series fits into a multi-modal future for generative AI. “Framing time series forecasting as natural language generation can be seen as another step towards unifying more capabilities within a single large and powerful model, in which understanding can be shared between many tasks and modalities,” they write in their concluding section.
The code for LLMTime is posted on GitHub.



